
[ad_1]
Life is full of tough binary choices.
Should I have that slice of pizza or not? Should I carry an umbrella or not?
While some decisions can be rightly made by weighing the pros and cons – for example, it’s better not to eat a slice of pizza as it contains extra calories – some decisions may not be that easy.
For instance, you can never be fully sure whether or not it’ll rain on a specific day. So the decision of whether or not to carry an umbrella is a tough one to make.
To make the right choice, one requires predictive capabilities. This ability is highly lucrative and has numerous real-world applications, especially in computers. Computers love binary decisions. After all, they speak in binary code.
Machine learning algorithms, more precisely the logistic regression algorithm, can help predict the likelihood of events by looking at historical data points. For example, it can predict whether an individual will win the election or whether it’ll rain today.
What is logistic regression?
Logistic regression is a statistical method used to predict the outcome of a dependent variable based on previous observations. It’s a type of regression analysis and is a commonly used algorithm for solving binary classification problems.
If you’re wondering what regression analysis is, it’s a type of predictive modeling technique used to find the relationship between a dependent variable and one or more independent variables.
An example of independent variables is the time spent studying and the time spent on Instagram. In this case, grades will be the dependent variable. This is because both the “time spent studying” and the “time spent on Instagram” would influence the grades; one positively and the other negatively.
Logistic regression is a classification algorithm that predicts a binary outcome based on a series of independent variables. In the above example, this would mean predicting whether you would pass or fail a class. Of course, logistic regression can also be used to solve regression problems, but it’s mainly used for classification problems.
Another example would be predicting whether a student will be accepted into a university. For that, multiple factors such as the SAT score, student’s grade point average, and the number of extracurricular activities will be considered. Using historical data about previous outcomes, the logistic regression algorithm will sort students into “accept” or “reject” categories.
Logistic regression is also referred to as binomial logistic regression or binary logistic regression. If there are more than two classes of the response variable, it’s called multinomial logistic regression. Unsurprisingly, logistic regression was borrowed from statistics and is one of the most common binary classification algorithms in machine learning and data science.
Did you know? An artificial neural network (ANN) representation can be seen as stacking together a large number of logistic regression classifiers.
Logistic regression works by measuring the relationship between the dependent variable (what we want to predict) and one or more independent variables (the features). It does this by estimating the probabilities with the help of its underlying logistic function.
Key terms in logistic regression
Understanding the terminology is crucial to properly decipher the results of logistic regression. Knowing what specific terms mean will help you learn quickly if you’re new to statistics or machine learning.
- Variable: Any number, characteristic, or quantity that can be measured or counted. Age, speed, gender, and income are examples.
- Coefficient: A number, usually an integer, multiplied by the variable that it accompanies. For example, in 12y, the number 12 is the coefficient.
- EXP: Short form of exponential.
- Outliers: Data points that significantly differ from the rest.
- Estimator: An algorithm or formula that generates estimates of parameters.
- Chi-squared test: Also called the chi-square test, it’s a hypothesis testing method to check whether the data is as expected.
- Standard error: The approximate standard deviation of a statistical sample population.
- Regularization: A method used for reducing the error and overfitting by fitting a function (appropriately) on the training data set.
- Multicollinearity: Occurrence of intercorrelations between two or more independent variables.
- Goodness of fit: Description of how well a statistical model fits a set of observations.
- Odds ratio: Measure of the strength of association between two events.
- Log-likelihood functions: Evaluates a statistical model’s goodness of fit.
- Hosmer–Lemeshow test: A test that assesses whether the observed event rates match the expected event rates.
What is a logistic function?
Logistic regression is named after the function used at its heart, the logistic function. Statisticians initially used it to describe the properties of population growth. Sigmoid function and logit function are some variations of the logistic function. Logit function is the inverse of the standard logistic function.
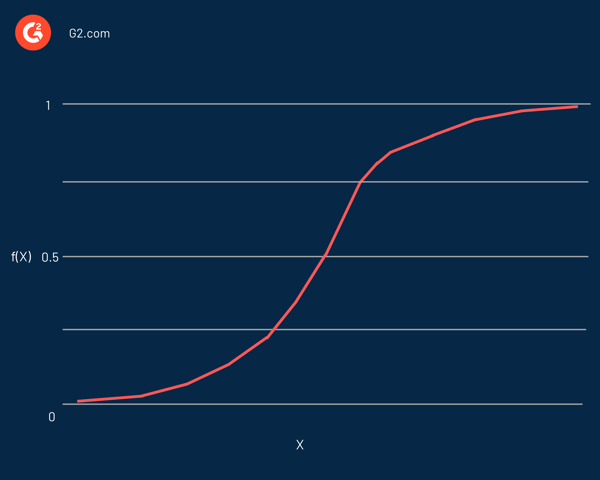
In effect, it’s an S-shaped curve capable of taking any real number and mapping it into a value between 0 and 1, but never precisely at those limits. It’s represented by the equation:
f(x) = L / 1 + e^-k(x – x0)
In this equation:
- f(X) is the output of the function
- L is the curve’s maximum value
- e is the base of the natural logarithms
- k is the steepness of the curve
- x is the real number
- x0 is the x values of the sigmoid midpoint
If the predicted value is a considerable negative value, it’s considered close to zero. On the other hand, if the predicted value is a significant positive value, it’s considered close to one.
Logistic regression is represented similar to how linear regression is defined using the equation of a straight line. A notable difference from linear regression is that the output will be a binary value (0 or 1) rather than a numerical value.
Here’s an example of a logistic regression equation:
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
In this equation:
- y is the predicted value (or the output)
- b0 is the bias (or the intercept term)
- b1 is the coefficient for the input
- x is the predictor variable (or the input)
The dependent variable generally follows the Bernoulli distribution. The values of the coefficients are estimated using maximum likelihood estimation (MLE), gradient descent, and stochastic gradient descent.
As with other classification algorithms like the k-nearest neighbors, a confusion matrix is used to evaluate the accuracy of the logistic regression algorithm.
Did you know? Logistic regression is a part of a larger family of generalized linear models (GLMs).
Just like evaluating the performance of a classifier, it’s equally important to know why the model classified an observation in a particular way. In other words, we need the classifier’s decision to be interpretable.
Although interpretability isn’t easy to define, its primary intent is that humans should know why an algorithm made a particular decision. In the case of logistic regression, it can be combined with statistical tests like the Wald test or the likelihood ratio test for interpretability.
When to use logistic regression
Logistic regression is applied to predict the categorical dependent variable. In other words, it’s used when the prediction is categorical, for example, yes or no, true or false, 0 or 1. The predicted probability or output of logistic regression can be either one of them, and there’s no middle ground.
In the case of predictor variables, they can be part of any of the following categories:
- Continuous data: Data that can be measured on an infinite scale. It can take any value between two numbers. Examples are weight in pounds or temperature in Fahrenheit.
- Discrete, nominal data: Data that fits into named categories. A quick example is hair color: blond, black, or brown.
- Discrete, ordinal data: Data that fits into some form of order on a scale. An example is telling how satisfied you’re with a product or service on a scale of one to five.
Logistic regression analysis is valuable for predicting the likelihood of an event. It helps determine the probabilities between any two classes.
In a nutshell, by looking at historical data, logistic regression can predict whether:
- An email is a spam
- It’ll rain today
- A tumor is fatal
- An individual will purchase a car
- An online transaction is fraudulent
- A contestant will win an election
- A group of users will buy a product
- An insurance policyholder will expire before the policy term expires
- A promotional email receiver is a responder or non-responder
In essence, logistic regression helps solve probability and classification problems. In other words, you can expect only classification and probability outcomes from logistic regression.
For example, it can be used to determine the probability of something being “true or false” and also for deciding between two outcomes like “yes or no”.
A logistic regression model can also help classify data for extract, transform, and load (ETL) operations. Logistic regression shouldn’t be used if the number of observations is less than the number of features. Otherwise, it may lead to overfitting.
Linear regression vs. logistic regression
While logistic regression predicts the categorical variable for one or more independent variables, linear regression predicts the continuous variable. In other words, logistic regression provides a constant output, whereas linear regression offers a continuous output.
Since the outcome is continuous in linear regression, there are infinite possible values for the outcome. But for logistic regression, the number of possible outcome values is limited.
In linear regression, the dependent and independent variables should be linearly related. In the case of logistic regression, the independent variables should be linearly related to the log odds (log (p/(1-p)).
Tip: Logistic regression can be implemented in any programming language used for data analysis, such as R, Python, Java, and MATLAB.
While linear regression is estimated using the ordinary least squares method, logistic regression is estimated using the maximum likelihood estimation approach.
Both logistic and linear regression are supervised machine learning algorithms and the two main types of regression analysis. While logistic regression is used to solve classification problems, linear regression is primarily used for regression problems.
Going back to the example of time spent studying, linear regression and logistic regression can predict different things. Logistic regression can help predict whether the student passed an exam or not. In contrast, linear regression can predict the student’s score.
Logistic regression assumptions
While using logistic regression, we make a few assumptions. Assumptions are integral to correctly use logistic regression for making predictions and solving classification problems.
The following are the main assumptions of logistic regression:
- There is little to no multicollinearity between the independent variables.
- The independent variables are linearly related to the log odds (log (p/(1-p)).
- The dependent variable is dichotomous or binary; it fits into two distinct categories. This applies to only binary logistic regression, which is discussed later.
- There are no non-meaningful variables as they might lead to errors.
- The data sample sizes are larger, which is integral for better results.
- There are no outliers.
Types of logistic regression
Logistic regression can be divided into different types based on the number of outcomes or categories of the dependent variable.
When we think of logistic regression, we most probably think of binary logistic regression. In most parts of this article, when we referred to logistic regression, we were referring to binary logistic regression.
The following are the three main types of logistic regression.
Binary logistic regression
Binary logistic regression is a statistical method used to predict the relationship between a dependent variable and an independent variable. In this method, the dependent variable is a binary variable, meaning it can take only two values (yes or no, true or false, success or failure, 0 or 1).
A simple example of binary logistic regression is determining whether an email is spam or not.
Multinomial logistic regression
Multinomial logistic regression is an extension of binary logistic regression. It allows more than two categories of the outcome or dependent variable.
It’s similar to binary logistic regression but can have more than two possible outcomes. This means that the outcome variable can have three or more possible unordered types – types having no quantitative significance. For example, the dependent variable may represent “Type A,” “Type B,” or “Type C”.
Similar to binary logistic regression, multinomial logistic regression also uses maximum likelihood estimation to determine the probability.
For example, multinomial logistic regression can be used to study the relationship between one’s education and occupational choices. Here, the occupational choices will be the dependent variable which consists of categories of different occupations.
Ordinal logistic regression
Ordinal logistic regression, also known as ordinal regression, is another extension of binary logistic regression. It’s used to predict the dependent variable with three or more possible ordered types – types having quantitative significance. For example, the dependent variable may represent “Strongly Disagree,” “Disagree,” “Agree,” or “Strongly Agree”.
It can be used to determine job performance (poor, average, or excellent) and job satisfaction (dissatisfied, satisfied, or highly satisfied).
Advantages and disadvantages of logistic regression
Many of the advantages and disadvantages of the logistic regression model apply to the linear regression model. One of the most significant advantages of the logistic regression model is that it doesn’t just classify but also gives probabilities.
The following are some of the advantages of the logistic regression algorithm.
- Simple to understand, easy to implement, and efficient to train
- Performs well when the dataset is linearly separable
- Good accuracy for smaller datasets
- Doesn’t make any assumptions about the distribution of classes
- It offers the direction of association (positive or negative)
- Useful to find relationships between features
- Provides well-calibrated probabilities
- Less prone to overfitting in low dimensional datasets
- Can be extended to multi-class classification
However, there are numerous disadvantages to logistic regression. If there’s a feature that would separate two classes perfectly, then the model can’t be trained anymore. This is called complete separation.
This happens mainly because the weight for that feature wouldn’t converge as the optimal weight would be infinite. However, in most cases, complete separation can be solved by defining a prior probability distribution of weights or introducing penalization of the weights.
The following are some of the disadvantages of the logistic regression algorithm:
- Constructs linear boundaries
- Can lead to overfitting if the number of features is more than the number of observations
- Predictors should have average or no multicollinearity
- Challenging to obtain complex relationships. Algorithms like neural networks are more suitable and powerful
- Can be used only to predict discrete functions
- Can’t solve non-linear problems
- Sensitive to outliers
When life gives you options, think logistic regression
Many might argue that humans don’t live in a binary world, unlike computers. Of course, if you’re given a slice of pizza and a hamburger, you can take a bite of both without having to choose just one. But if you take a closer look at it, a binary decision is engraved on (literally) everything. You can either choose to eat or not eat a pizza; there’s no middle ground.
Evaluating the performance of a predictive model can be tricky if there’s a limited amount of data. For this, you can use a technique called cross-validation, which involves partitioning the available data into a training set and a test set.
[ad_2]
Source link